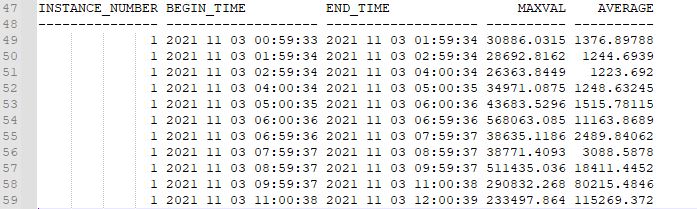
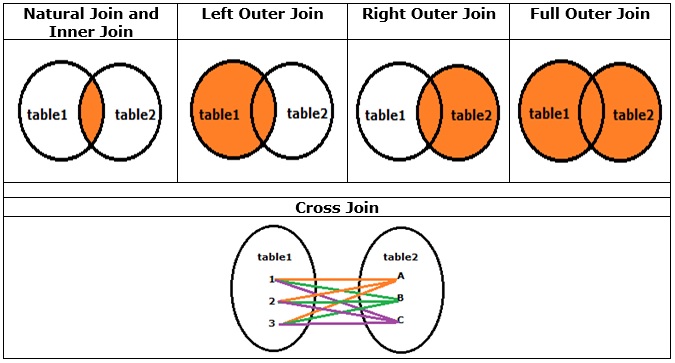
SQL Join forms a temporary table and visualizes the final output from it. So there is no possibility of alteration in associated tables’ structure and data.
SQL Join has the reverse effect of normalization. During normalization, tables get split into more specific tables with a relationship between them. Also, there will be a minimal amount of duplicate and NULL values in each table. Join invokes the same relationship to construct a temporary table that contains the expected result. For several types of joins, this temporary table is de-normalized in nature containing NULL and duplicate values.